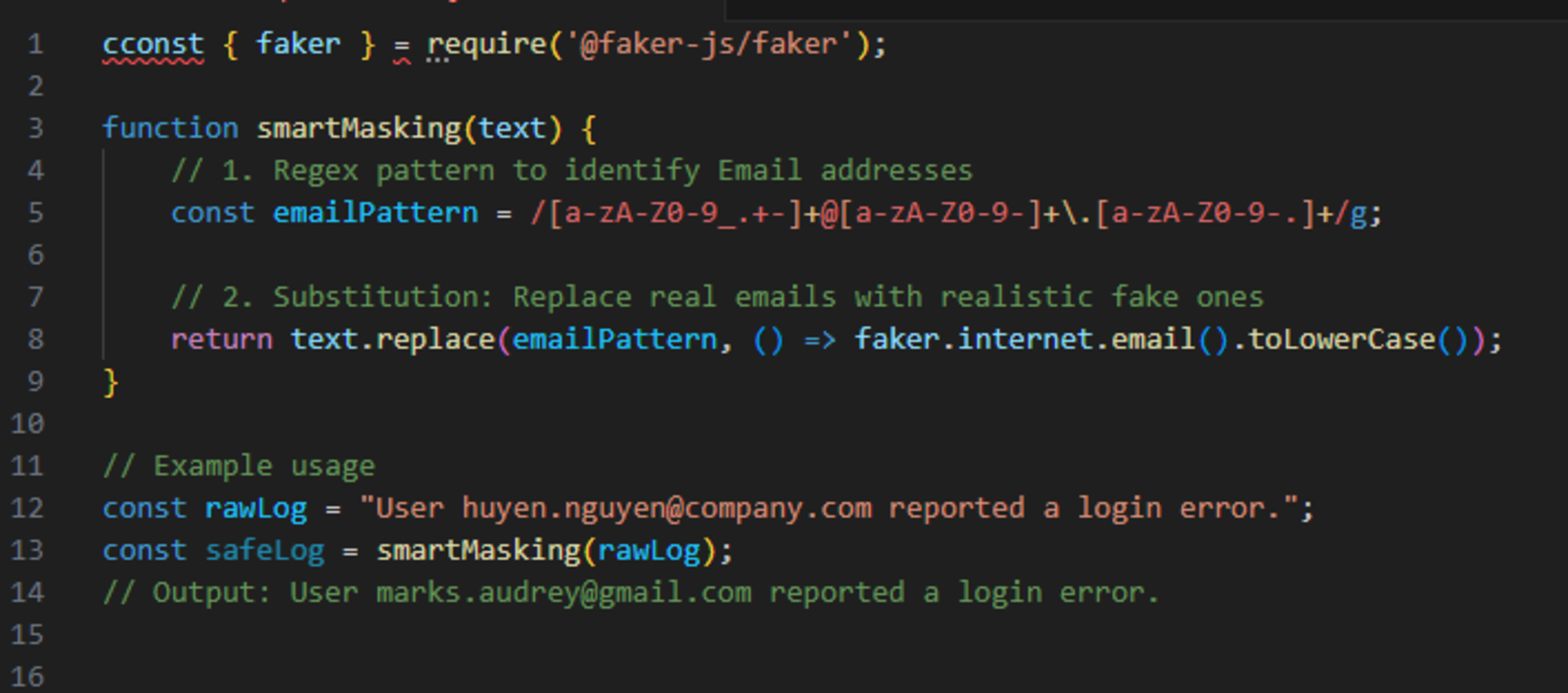
In the Python world, for loops are our bread and butter. They are readable and fit the way we think about logic: process one item, then the next.
- Process User A -> Done.
- Process Order B -> Done.
This "row-by-row" thinking works great for complex business logic. However, I recently encountered a scenario where this approach became a bottleneck. I needed to perform simple calculations on a large dataset (10 million records), and I realized my standard approach was leaving performance on the table.
This post shares how I learned to stop looping and start vectorizing, reducing execution time significantly.
The Comfort Zone: The "Universal Loop"
Let's look at a simple problem: Calculate the sum of squares for the first 10 million integers.
Thinking procedurally, the most natural solution is to iterate through the range and add up the results.
import time
def sum_squares_loop(n):
result = 0
for i in range(n):
result += i * i
return result
# Running with 10 million records
N = 10_000_000
start_time = time.time()
print(f"Result: {sum_squares_loop(N)}")
print(f"Execution Time (Loop): {time.time() - start_time:.4f} seconds")
The Reality Check:
Running this on Python 3.11, it takes about 0.34 seconds.
You might say: "0.34 seconds is fast enough!" And for a single run, you are right. Python 3.11 has done an amazing job optimizing loops compared to older versions.
But what if you have to run this calculation 100 times a second? Or what if the dataset grows to 1 billion rows? That "fast enough" loop quickly becomes a bottleneck.
The Shift: Thinking in Sets (Vectorization)
To optimize this, we need to change our mental model. Instead of telling the CPU: "Take number 1, square it. Take number 2, square it...", we want to say: "Take this entire array of numbers and square them all at once."
This is called Vectorization.
By using a library like NumPy, we can push the loop down to the C layer, where it's compiled and optimized (often utilizing CPU SIMD instructions).
Here is the same logic, rewritten:
import numpy as np
import time
def sum_squares_vectorized(n):
# Create an array of integers from 0 to n-1
arr = np.arange(n)
# The operation is applied to the entire array at once
return np.sum(arr * arr)
# Running with 10 million records
N = 10_000_000
start_time = time.time()
print(f"Result: {sum_squares_vectorized(N)}")
print(f"Execution Time (Vectorized): {time.time() - start_time:.4f} seconds")
The Result: This runs in roughly 0.036 seconds.
Performance Comparison
| Method | Execution Time | Relative Speed |
| Standard For Loop (Python 3.11) | ~0.340s | 1x |
| Vectorized Approach | ~0.036s | ~10x |
We achieved a 10x speedup simply by changing how we access and process the data.
A Crucial Observation: The Cost of Speed
If you run the code above closely, you might notice something strange: The results might differ.
- Python Loop: Returns the correct, massive number (≈ 3.3 × 10²⁰).
- Vectorized (NumPy): Might return a smaller or negative number (due to overflow).
Why?
This highlights a classic engineering trade-off: Safety vs. Speed.
- Python Integers are arbitrary-precision objects. They can grow infinitely to hold any number, but they are heavy and slow to process.
- NumPy Integers are fixed-size (usually int64 like in C). They are incredibly fast because they fit perfectly into CPU registers, but they can overflow if the number gets too big.
The takeaway: In this benchmark, we are measuring the engine speed, not checking the math homework. When using vectorized tools in production, always be mindful of your data types (e.g., using float64 or object if numbers are astronomical)!
Lessons for Scalable Software
While NumPy is a specific tool, the concept of Set-based operations applies everywhere in software engineering, from database queries to backend APIs.
- Batch Your Database Queries:
Avoid the "N+1 problem" (looping through a list of IDs and querying the DB for each one). Instead, use WHERE id IN (...) to fetch everything in a single set-based query. - Minimize Context Switching:
Every time your code switches layers (App <-> DB, Python <-> C), there is a cost. Vectorization minimizes this cost by processing data in chunks rather than single items.
Conclusion
Loops are an essential part of programming, but they aren't always the right tool for the job. When performance matters, especially with large collections of data, try to think in sets rather than steps.
It’s a small shift in mindset that pays huge dividends in performance.
[References]
https://wiki.python.org/moin/PythonSpeed/PerformanceTips
https://realpython.com/numpy-array-programming/
Ready to get started?
Contact IVC for a free consultation and discover how we can help your business grow online.
Contact IVC for a Free Consultation