Understanding Vector Databases: What, How, and Why They Matter in AI
If you've been exploring the world of artificial intelligence (AI), you might have come across the term "vector database." This concept is gaining traction, especially with applications like image recognition, natural language processing, and recommendation systems. But what exactly is a vector database, and why is it so valuable in these contexts? In this blog post, we'll dive into what a vector database is, how it works, and why you should consider using it for your AI projects.
What is a Vector Database?
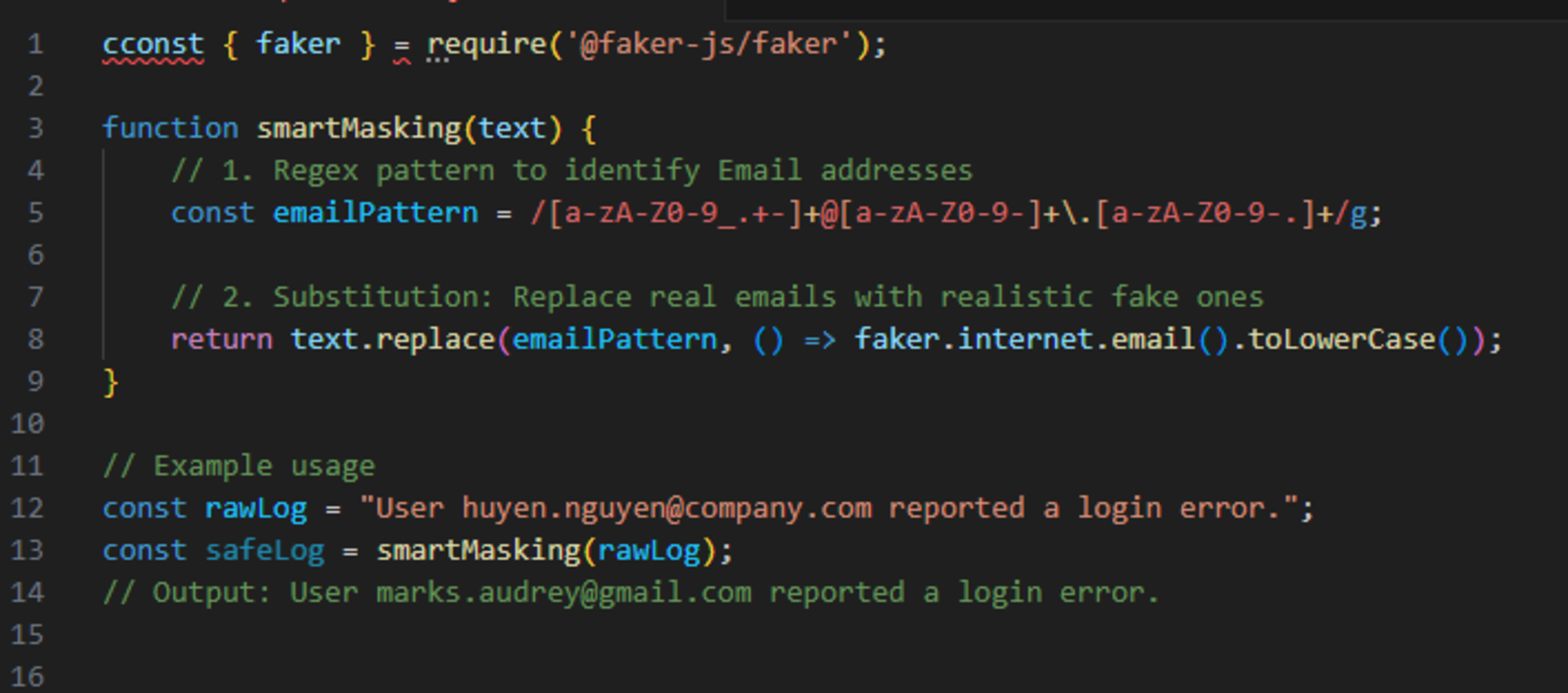
At its core, a vector database is a specialized type of database optimized to store and search through high-dimensional vector data. Vectors are numerical arrays that can represent complex entities such as images, texts, videos, or audio signals. Think of a vector as a way to translate real-world items into numerical representations that an AI model can understand. For instance, an image of a cat can be transformed into a numerical array (a vector) where each number captures a particular feature of the cat, such as color, shape, or texture.
Unlike traditional relational databases that store data in rows and columns, vector databases are designed to efficiently manage and search high-dimensional vectors by leveraging the spatial relationships between them. Essentially, it allows for similarity searches—finding data items that are "close" to a given vector in a high-dimensional space, making them ideal for tasks like content recommendation, clustering, or finding similar items.
How Does a Vector Database Work?
The main job of a vector database is to allow quick similarity searches. Imagine you have a database filled with images, and you want to find other images that are similar to one you just uploaded. In a traditional database, you might store metadata about the image—such as its title or tags—and perform a search based on these attributes. But if you wanted to compare images based purely on their visual content, you'd need a vector database.
Vector databases work by using algorithms that measure how "close" two vectors are to each other in the vector space. This concept of closeness is referred to as distance metrics, commonly cosine similarity or Euclidean distance. These metrics help determine which vectors (and thus the items they represent) are most similar to a given input.
To speed up these similarity searches, vector databases use Approximate Nearest Neighbor (ANN) algorithms. ANN algorithms help find the closest vectors efficiently, even when working with millions or billions of items. There are different types of ANN algorithms:
- Hashing-based methods: These create a compact representation of vectors to enable quick search.
- Tree-based methods: These are like decision trees but for finding nearest neighbors.
- Graph-based methods: These use relationships between vectors in a network-like structure to identify similarities.
Different vector databases might use different types of ANN algorithms, and some even allow customization to fit specific use cases.
Examples of Vector Database Applications
To understand why vector databases are so powerful, let’s look at some real-world scenarios where they shine:
1. Image Search - Workflow for Image Similarity Search:
- Feature Extraction: Use a convolutional neural network (CNN) to extract features from images and convert them into vectors.
- Storing Vectors: Store the extracted vectors in a vector database like Pinecone or Weaviate.
- Query: When a user uploads an image, the system converts it to a feature vector using the trained CNN model.
- Similarity Search: The vector database finds the closest matches using similarity metrics.
- Return Results: Retrieve the most similar images and present them to the user.
Diagram for Image Search Workflow:
|
SQL-like Pseudo Query:
Imagine we have an image_features table storing vectors:
※In this query, |
2. Text Search
Semantic Search Diagram:
|
Pseudo SQL-like Query:
SELECT document_idFROM document_vectorsORDER BY cosine_similarity(vector, [query_vector]) DESC LIMIT 5; |
3. Audio Recognition - Workflow for Audio Similarity Search:
- Convert Audio to Feature Vector: Extract audio features (e.g., using Fast Fourier Transform - FFT).
- Store in Vector Database: Save these vectors in the database.
- User Query via Humming: The user hums, and the system converts it to a feature vector.
- Search Similar Audio: Find similar vectors.
- Return Matching Songs: Return a list of songs similar to the hum.
Diagram for Audio Search Workflow:
|
4. Recommendation Systems - Recommendation Workflow for a Movie Streaming Platform:
- User Vector Representation: Each user is represented by a vector based on their preferences.
- Movie Vector Representation: Each movie also has a corresponding vector.
- Find Similar Movies: The system finds movies similar to what the user has previously liked.
- Return Recommendations: Recommendations are returned to the user.
Diagram for Recommendation System:
|
SQL-like Pseudo Query for Recommendation:
SELECT movie_idFROM movie_vectorsORDER BY cosine_similarity(vector, [user_vector]) DESCLIMIT 5; |
Why Should You Use a Vector Database?
1. Efficient High-Dimensional Search
Traditional databases are optimized for storing structured data and performing queries using exact matches. However, AI-based applications often require searches based on similarity rather than exact matching. Vector databases make this feasible by leveraging specialized indexing techniques that make finding similar vectors incredibly efficient, even in large datasets.
2. Scalability for Large AI Applications
Many AI applications deal with large amounts of data—images, videos, texts, or even sensor data from IoT devices. Performing similarity searches across millions or billions of high-dimensional vectors is computationally expensive. Vector databases are designed to handle this kind of workload by providing low-latency responses and high throughput.
3. Flexibility in AI Applications
Another reason to use vector databases is their flexibility. They work with any data type that can be vectorized—images, text, audio, etc. This makes them a versatile choice for AI applications where you might need to combine different data types, such as using both text and images to recommend articles.
Conclusion
Vector databases are a transformative technology that has enabled a range of advanced AI applications—from recommendation engines to semantic searches. They allow us to take high-dimensional data, represent it meaningfully, and efficiently find similar items, all at scale. Whether you’re working on enhancing search capabilities for an e-commerce store, building a recommendation system for a media platform, or enabling semantic searches in a text-heavy application, vector databases are an excellent fit.
As AI and machine learning continue to evolve, we can expect vector databases to play an even more critical role, making complex similarity-based tasks faster and more accessible. If you haven’t experimented with vector databases yet, now is a great time to start—it's a step towards unlocking richer, smarter, and more responsive AI-driven user experiences.
※ References:
(1) What Is a Vector Database? | IBM. https://www.ibm.com/topics/vector-database
(2) Vector database - Wikipedia. https://en.wikipedia.org/wiki/Vector_database
(3) What is a Vector Database? - Vector Databases Explained - AWS. https://aws.amazon.com/what-is/vector-databases/
(4) The 5 Best Vector Databases | A List With Examples | DataCamp. https://www.datacamp.com/blog/the-top-5-vector-databases