June 4, 2026
What Is Adaptive Software Development (ASD)? A Practical Guide for Modern Engineering Teams
Deadlines shift. Requirements change. Markets move faster than roadmaps.
For engineering teams working in complex, unpredictable environments, traditional plan-driven development often creates more friction than it solves. That's where Adaptive Software Development (ASD) comes in.
Introduced by Jim Highsmith and Sam Bayer in the mid-1990s, ASD was built on a simple premise: embrace change, don't fight it. Instead of locking in requirements upfront, ASD teams operate in short cycles of speculation, collaboration, and learning. They continuously adapt based on real feedback.
In this guide, we break down what ASD is, how it works, how it compares to Agile and Waterfall, and how modern engineering teams, including distributed and offshore teams, are applying it in practice.
What Is Adaptive Software Development (ASD)?

Adaptive Software Development (ASD) is an iterative software development methodology in which teams work in repeating cycles of Speculate, Collaborate, and Learn to build complex systems while continuously responding to change. It was introduced by Jim Highsmith and Sam Bayer and helped shape the principles later formalized in the Agile Manifesto.
Unlike methodologies that attempt to eliminate uncertainty, ASD treats uncertainty as a given, and designs the process around it.
The ASD Market: Why This Methodology Is Growing

Adaptive Software Development is gaining momentum as both engineering practices and the market itself demand more flexibility.
According to Gartner, the custom software development services market is growing at a compound annual growth rate of 8.9% and is expected to exceed $283 billion by 2028. This trend suggests that demand for software continues to expand, along with the complexity of building it.
As the market grows, so does the pressure on engineering teams. Products evolve mid-cycle, customer expectations shift, and new technologies continuously reshape development. In this context, rigid, plan-driven models can struggle to keep up, which is where ASD becomes increasingly relevant.
Insights from Forrester's The State Of Agile Development, 2025 also point in a similar direction. 95% of professionals say Agile remains critical to their operations, and 58% of business and technology leaders are prioritizing it in 2025. In addition, 61% of organizations have been using Agile for more than five years. This suggests that iterative and adaptive ways of working are now widely established.
At the same time, there appears to be a shift in focus. As Agile matures, teams are placing more emphasis on adaptability itself rather than strictly following predefined frameworks. ASD builds on this foundation by treating change and uncertainty as core conditions to design for.
What's driving adoption?
Three key factors are accelerating ASD adoption:
- The rise of distributed teams. As organizations become more global, coordination can no longer rely on rigid processes or constant real-time communication. Flexible frameworks help teams stay aligned while working asynchronously.
- The acceleration of product cycles. Teams are expected to release, test, and iterate much faster than before. Requirements often change during development, and methodologies that assume stability can struggle in this environment. ASD is designed to absorb and respond to that kind of change.
- The growth of offshore development. Working across regions introduces challenges in communication and alignment, and overly prescriptive processes tend to break down. ASD provides a balance by offering enough structure to maintain alignment while remaining flexible enough for distributed collaboration.
The 3 Phases of ASD
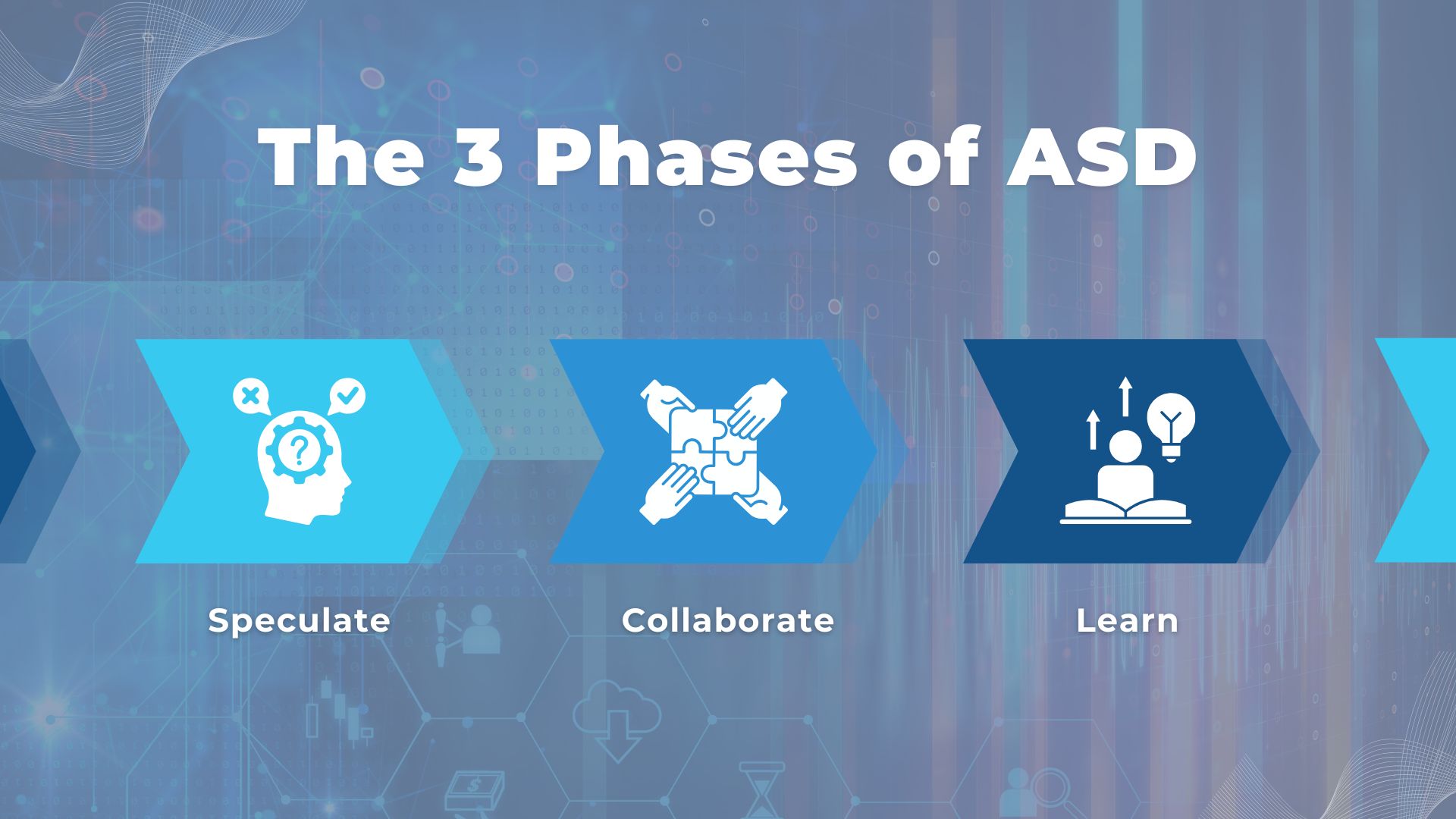
Adaptive Software Development is built around a simple but powerful cycle of Speculate, Collaborate, and Learn. Instead of following a fixed sequence, teams repeat these three phases continuously, using each iteration to refine both the product and the process based on real-world feedback.
Phase 1: Speculate
In ASD, planning starts with speculation rather than prediction. Teams define a clear direction and set of goals, but they avoid locking themselves into detailed, long-term plans that assume certainty. Instead, they identify key assumptions, risks, and unknowns, then create a flexible roadmap that can evolve as new information emerges. This approach allows teams to move forward with intent while staying open to change, which is critical in fast-moving or unclear environments.
Phase 2: Collaborate
Collaboration is where execution happens, and in ASD it is treated as a core capability rather than a supporting activity. Cross-functional teams work closely together, sharing context, solving problems in real time, and maintaining continuous communication with stakeholders. The focus is on collective ownership, not isolated roles, which helps reduce misalignment and accelerates decision-making. This becomes especially important in distributed or offshore setups, where strong collaboration practices are the difference between progress and friction.
Phase 3: Learn
Every iteration ends with deliberate learning. Teams gather feedback from users, stakeholders, and internal reviews, then use those insights to refine both the product and the way they work. This phase is not just about identifying what went wrong, but also about reinforcing what worked and why. Over time, this continuous learning loop helps teams make better decisions, reduce risk, and adapt more effectively to changing conditions.
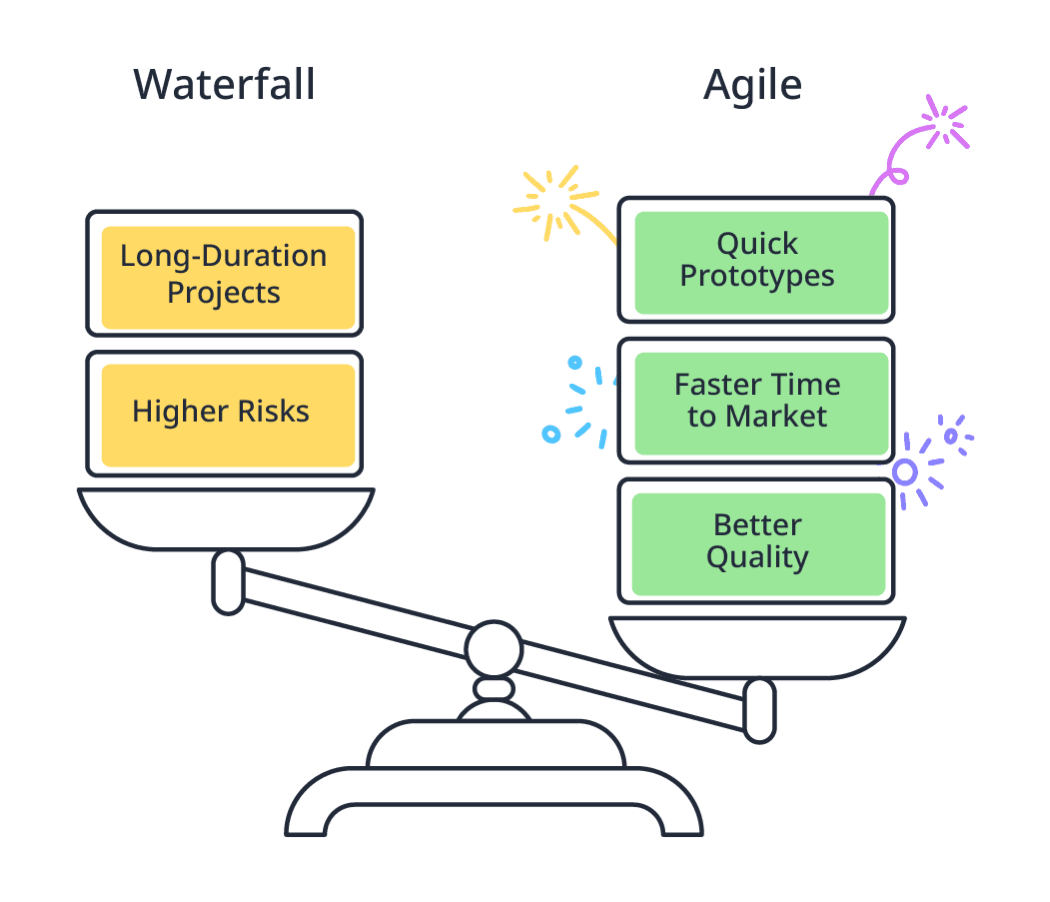
ASD vs. Agile vs. Waterfall: Key Differences

Each methodology approaches planning, change, and execution differently. Understanding these differences helps you choose the right model based on your project's level of uncertainty, speed requirements, and team structure.
| Aspect | ASD | Agile | Waterfall |
|---|---|---|---|
| Core Approach | Fully adaptive and change-driven | Iterative with structured cycles | Linear and plan-driven |
| Planning Style | High-level, speculative planning | Sprint-based planning | Detailed upfront planning |
| Handling Change | Change is expected and embraced continuously | Managed within sprint boundaries | Difficult and costly to implement |
| Development Cycle | Continuous phases (speculate, collaborate, learn) | Time-boxed iterations (sprints) | Sequential phases (design, build, test) |
| Collaboration | Deep, ongoing collaboration across all roles | Strong within teams, structured ceremonies | Limited, often siloed by phase |
| Feedback Timing | Continuous and integrated into each cycle | Regular, typically at sprint reviews | Late-stage, often after development |
| Risk Management | Addressed early and revisited continuously | Managed per iteration | Identified early but often revisited late |
| Best Fit | Complex, uncertain, fast-changing projects | Product-focused teams needing flexibility | Stable, predictable projects with fixed scope |
7 Core Principles of Adaptive Software Development

Adaptive Software Development is built on a set of principles that prioritize flexibility, collaboration, and continuous improvement in fast-changing environments.
- 1. Adaptability
ASD emphasizes adaptive, high-level planning over rigid, detailed roadmaps. Teams focus on direction rather than fixed outcomes, allowing them to adjust quickly as requirements or market conditions evolve. - 2. Collaborative Environment
Open communication and strong teamwork are central to ASD. Teams are encouraged to share ideas, align frequently, and build a culture where collaboration drives better outcomes. - 3. Continuous Learning
Each iteration is an opportunity to learn. Feedback from users, stakeholders, and internal reviews is continuously incorporated to improve both the product and the development process. - 4. Iterative Development
Development is broken into small, manageable increments. Each cycle delivers working software, making it easier to validate progress and adapt without large-scale disruption. - 5. Responsive to Change
ASD is designed to handle change at any stage. Teams are structured to respond quickly to new requirements, technologies, or market shifts without slowing down delivery. - 6. Risk Management
Risks are identified early and addressed continuously. Instead of avoiding uncertainty, teams actively manage it as part of the development process. - 7. Empowerment and Ownership
Teams are trusted to make decisions and take responsibility for outcomes. This sense of ownership improves accountability, speed, and overall execution quality.
When Should You Use ASD?

ASD is a powerful methodology, but it works best in environments where change is constant and feedback can be acted on quickly. The key is knowing whether your project actually needs that level of flexibility.
The Best Use Cases for ASD
ASD is well suited for projects where requirements evolve over time, such as startups or new product development. It works best when teams can operate autonomously and make decisions without heavy approval layers. Active stakeholder involvement is also important, since continuous feedback drives progress. ASD is a strong fit for complex systems that need to be built incrementally, and for offshore or distributed teams that require a flexible way to stay aligned across locations.
When ASD Is Not the Right Choice
ASD is less effective when requirements are fixed from the start, such as in regulated or compliance-heavy projects. It also breaks down when stakeholders cannot provide ongoing feedback. Teams that are new to adaptive ways of working may struggle without proper support. For small, stable projects with minimal change, a simpler approach is often more efficient.
ASD and Offshore Teams: What to Look For
Using ASD with offshore teams requires more than adopting a framework. Strong communication habits are essential to keep everyone aligned across time zones. Teams need engineers who can work independently and take ownership, along with a culture of transparency where issues are surfaced early.
This is where many offshore partnerships fail. The challenge is not skill, but execution and alignment.
If you are evaluating an offshore partner, focus on whether they can operate in an adaptive, feedback-driven model in a distributed environment.
At ISB Vietnam (IVC), this is where the difference becomes clear. By combining ASD with Japanese-quality disciplined communication practices, teams stay aligned without losing flexibility. More importantly, the focus is not just on delivering a single project, but on building a process that continuously improves over time.
If you are looking for a long-term offshore partner that can evolve with your product, not just execute tasks, contact IVC to explore how we can support your next phase of growth.
Contact IVC TodayHow ASD Works in Offshore Development Teams

Applying ASD in offshore environments is not just about adopting a methodology. It requires aligning process, communication, and team structure to handle distance, time zones, and evolving requirements.
Why ASD suits offshore partnerships
Offshore development introduces natural complexity. Time zone gaps, communication delays, and cultural differences can quickly create misalignment. ASD helps reduce this risk by working in short cycles, emphasizing continuous feedback, and encouraging close collaboration. Instead of relying on fixed plans, teams adjust frequently, which makes it easier to stay aligned even when conditions change.
How IVC applies ASD principles in client projects
At ISB Vietnam (IVC), ASD is applied with a focus on execution discipline. "Speculate" is guided by real business context rather than assumptions. "Collaborate" is supported by structured communication practices, ensuring transparency across teams. "Learn" is treated as an operational process, where insights from each cycle are documented and reflected in both product and workflow improvements. This approach allows projects to stay flexible without losing control.
Communication cadence for distributed ASD teams
For ASD to work in distributed teams, communication needs to be intentional:
- Daily asynchronous updates help maintain visibility without slowing teams down.
- Weekly syncs are used for decision-making rather than status reporting.
- Iteration reviews provide real stakeholder feedback.
- Retrospectives are used to improve how the team works. This cadence creates alignment without relying on constant real-time interaction.
ASD and Japanese Quality Standards: A Natural Fit

In the unpredictable world of R&D, rigid plans are the enemy of innovation. At IVC, we navigate the "unknowns" of our clients' most ambitious projects by combining the rapid flexibility of Adaptive Software Development (ASD) with the uncompromising discipline of Japanese Quality Management. Here's how this unique synergy transforms shifting requirements into high-quality results.
The "Soul" of the Sprint: Why ASD and Japanese Quality are a Perfect Match
When a client approaches us with an R&D project, the requirements are rarely set in stone. In our AI-powered VR Chat tool project, the goals shifted every time the client saw a new prototype.
While others might struggle with "scope creep", we use it as fuel. We've found a natural harmony between the three phases of ASD and the foundational principles of Japanese Quality Management. In our workflow, Japanese values aren't just cultural additions, they are the "engine" driving each phase.
Speculate: Staying Agile Through Shifting Requirements
In the Speculate phase, we don't lock ourselves into a rigid, year-long plan. Because the client's priorities changed weekly, we updated our roadmap every cycle. This allowed us to treat the client's evolving vision as a strength rather than a distraction, ensuring the project always moved toward their latest goal.
Collaborate: Horenso as the Communication Engine
In a fast-paced AI project, doing is not enough. We have to communicate. This is where Horenso (Report, Update, Consult) becomes vital during the Collaborate phase.
Strategic Soudan (Consultation):
During this project, we were under immense pressure to deliver measurable results in only one month. When the AI analyzed meeting notes and suggested a massive wish list of features, the easiest path would have been to try and build them all poorly.
The "One-Month Quality" Logic:
Instead, we used Soudan to advise the client to focus on just two core features. Why? Because in a high-speed R&D environment, it is better to have two features that are fully functional, tested, and integrated than ten features that crash. This narrow focus allowed us to run the entire flow from AI coding to rigorous manual testing, maintaining Japanese quality standards even under a tight deadline.
Learn: Kaizen as a Feedback Engine
The Learn phase aligns closely with Kaizen (continuous improvement). We review not only what was built, but how it was built.
When issues occurred, such as logic errors from AI outputs, we addressed root causes by refining prompts rather than applying temporary fixes. We also measured AI productivity against human benchmarks to identify inefficiencies. These insights were fed into the next cycle, improving both speed and reliability over time.
The IVC Advantage
For our clients, this means an R&D project doesn't just adapt to their changing ideas. It gets smarter and more reliable with every iteration. We don't just build software. We refine a living process through the PDCA (Plan-Do-Check-Act) cycle.
ASD's Speculate-Collaborate-Learn framework gives us the flexibility to pivot, but Japanese Horenso and Kaizen give us the engine to deliver excellence. That is the IVC promise.
FAQ: Adaptive Software Development

Below are answers to questions we hear most often from CTOs and engineering leads evaluating adaptive methodologies for their offshore projects.
Q: What is the difference between ASD and Agile?
ASD is closely related to Agile but places a stronger emphasis on continuous adaptation in uncertain environments. While Agile typically organizes work into structured sprints, ASD focuses on an ongoing cycle of Speculate, Collaborate, and Learn, allowing teams to adjust more fluidly as conditions change.
Q: What are the three phases of Adaptive Software Development?
The three phases are Speculate, Collaborate, and Learn. Teams first set direction and assumptions, then execute through close collaboration, and finally gather feedback to refine both the product and the process.
Q: Is Adaptive Software Development suitable for offshore teams?
Yes, ASD can work very well with offshore teams when supported by strong communication practices, clear ownership, and continuous feedback loops. It is particularly effective in distributed environments where flexibility and alignment are both required.
Q: Who created Adaptive Software Development?
ASD was introduced by Jim Highsmith and Sam Bayer in the 1990s.
Q: What types of projects benefit most from ASD?
ASD is best suited for projects with high uncertainty, evolving requirements, and complex systems. It is commonly used in startup environments, new product development, and situations where continuous stakeholder feedback is available.
Conclusion

Adaptive Software Development (ASD) gives modern engineering teams a practical way to operate in uncertainty. Instead of trying to predict everything upfront, ASD allows teams to move forward with direction, adapt through collaboration, and improve continuously through learning. This makes it especially valuable for fast-moving products, evolving requirements, and distributed development environments.
For CTOs and engineering leaders, the takeaway is straightforward. The challenge is no longer choosing between speed and quality. The real challenge is building a system that can deliver both, even as conditions change.
If you are scaling your product and considering offshore development, the methodology alone is not enough. Execution, communication, and long-term alignment are what make the difference.
Contact IVC to see how we apply ASD in real-world offshore projects and build partnerships that evolve with your business.
Contact IVC TodaySources / References
Data and insights in this article are based on the following sources:
- Gartner. Custom Software Development Services Market.
- Forrester. The State Of Agile Development, 2025: Amid The AI Hype, Agile Still Remains Relevant.