December 7, 2024
CakePHP 4: How to implement authorization.
In the previous sections, I introduced how to create a login feature for a website developed based on the CakePHP framework.
CakePHP 4: How to Create a Login Function.
CakePHP 4: How to Create a Token-Based Login Function.
In this article, I introduce how to implement authorization in an application using the CakePHP framework by utilizing the Authorization plugin.
1, Installation
We install the plugin with composer using the command below:
php composer.phar require "cakephp/authorization:^2.0"
The Authorization plugin integrates with the CakePHP application as both a middleware layer and a component to easily check authorization. In src/Application.php, implement the AuthorizationServiceProviderInterface interface and implement the getAuthorizationService() function as shown below.
class Application extends BaseApplication implements AuthenticationServiceProviderInterface, AuthorizationServiceProviderInterface
{
/**
* getAuthenticationService
* @param ServerRequestInterface $request
*/
public function getAuthorizationService(ServerRequestInterface $request): AuthorizationServiceInterface
{
$resolver = new OrmResolver();
return new AuthorizationService($resolver);
}
}
In the bootstrap() function, add the plugin as shown below:
/**
* Load all the application configuration and bootstrap logic.
*
* @return void
*/
public function bootstrap(): void
{
// Call parent to load bootstrap from files.
parent::bootstrap();
// …
// Load more plugins here
$this->addPlugin('Authentication');
$this->addPlugin('Authorization');
}
In the middleware() function, add the AuthorizationMiddleware.
/**
* Setup the middleware queue your application will use.
*
* @param \Cake\Http\MiddlewareQueue $middlewareQueue The middleware queue to setup.
* @return \Cake\Http\MiddlewareQueue The updated middleware queue.
*/
public function middleware(MiddlewareQueue $middlewareQueue): MiddlewareQueue
{
$middlewareQueue
// …
->add(new BodyParserMiddleware())
->add(new AuthenticationMiddleware($this))
->add(new AuthorizationMiddleware($this));
return $middlewareQueue;
}
In src/Controller/AppController.php, load the Authorization component in the initialize() function.
class AppController extends Controller
{
/**
* Initialization hook method.
*
* Use this method to add common initialization code like loading components.
*
* e.g. `$this->loadComponent('FormProtection');`
*
* @return void
*/
public function initialize(): void
{
parent::initialize();
// …
$this->loadComponent('Authentication.Authentication');
$this->loadComponent('Authorization.Authorization', [
'skipAuthorization' => [
'login','webLogin', 'logout' // functions do not need to check authorization.
]
]);
}
}
2, Policies.
Policies are classes that resolve permissions for a given object. These classes will be stored in the src/Policy directory. We can generate a policy class for an entity or table using CakePHP's bake.
# Create an entity policy
bin/cake bake policy --type entity Article
# Create a table policy
bin/cake bake policy --type table Articles
3, Implement.
In this article, I will implement API authorization requirements in the table below using policy.
| Title | endpoints | remark |
| Update an Article (PUT) | /api/articles/{id}.json | Can only be used by authenticated article writer users. |
| See like count on an article(GET) | /api/articles/{article_id}/likes.json | All users can see like count on an article. |
For the API Update an Article (PUT), can only be used by authenticated article writer users. We check if the logged-in user is the owner of the article to determine the edit permissions.
class ArticlePolicy
{
// …
/**
* Check if $user can edit Article
*
* @param \Authorization\IdentityInterface $user The user.
* @param \App\Model\Entity\Article $article
* @return bool
*/
public function canEdit(IdentityInterface $user, Article $article): Result
{
$isAuthor = $this->isAuthor($user, $article);
if ($isAuthor) {
return new Result(true);
}
return new Result(false, 'Permission denied');
}
protected function isAuthor(IdentityInterface $user, Article $article)
{
return $user->getIdentifier() === $article->user_id;
}
}
For the API See like count on an article(GET), all users can see like count on an article. In the LikePolicy class, the canView() function returns true so that all users can see the number of likes on the article.
/**
* Likes policy
*/
class LikesPolicy
{
/**
* Check if $user can view Likes
*
* @param \Authorization\IdentityInterface $user The user.
* @param \App\Model\Entity\Likes $likes
* @return bool
*/
public function canView(IdentityInterface $user, Likes $likes)
{
return true;
}
}
4, Testing.
For the API Update an Article (PUT), update the article with the user as the owner.
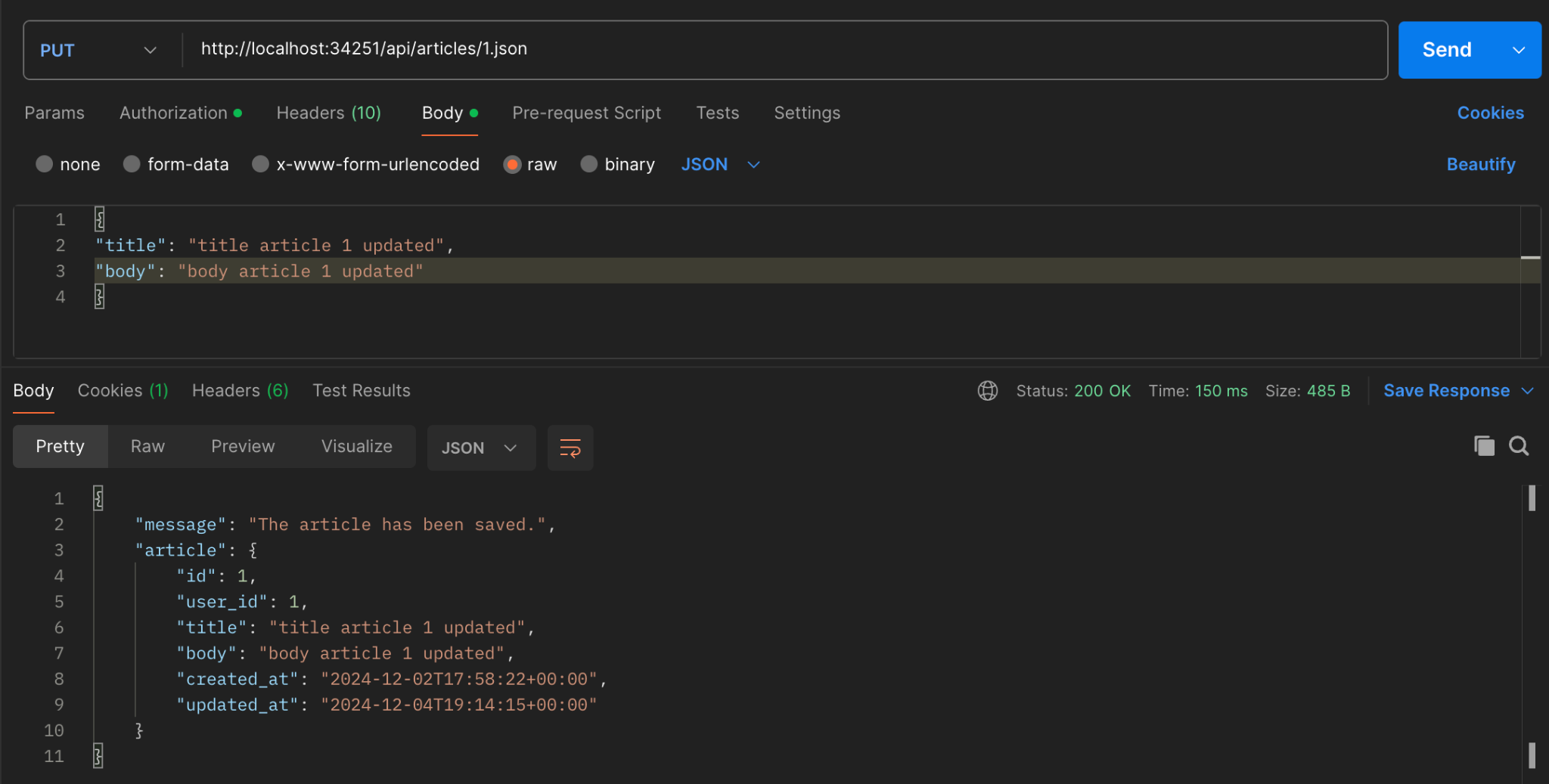
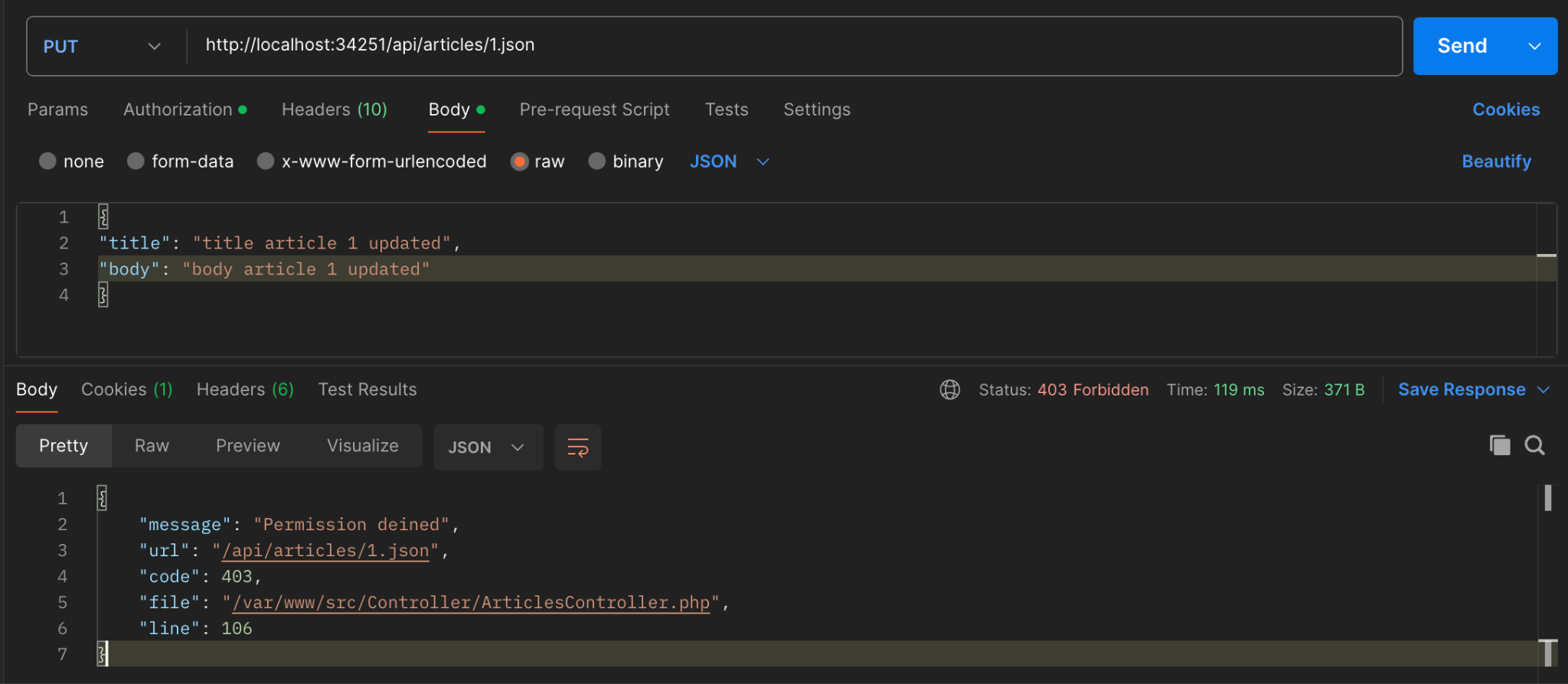
For the API Update an Article (PUT), update the article with a user who is not the owner. The expected result is that the article will not be updated.
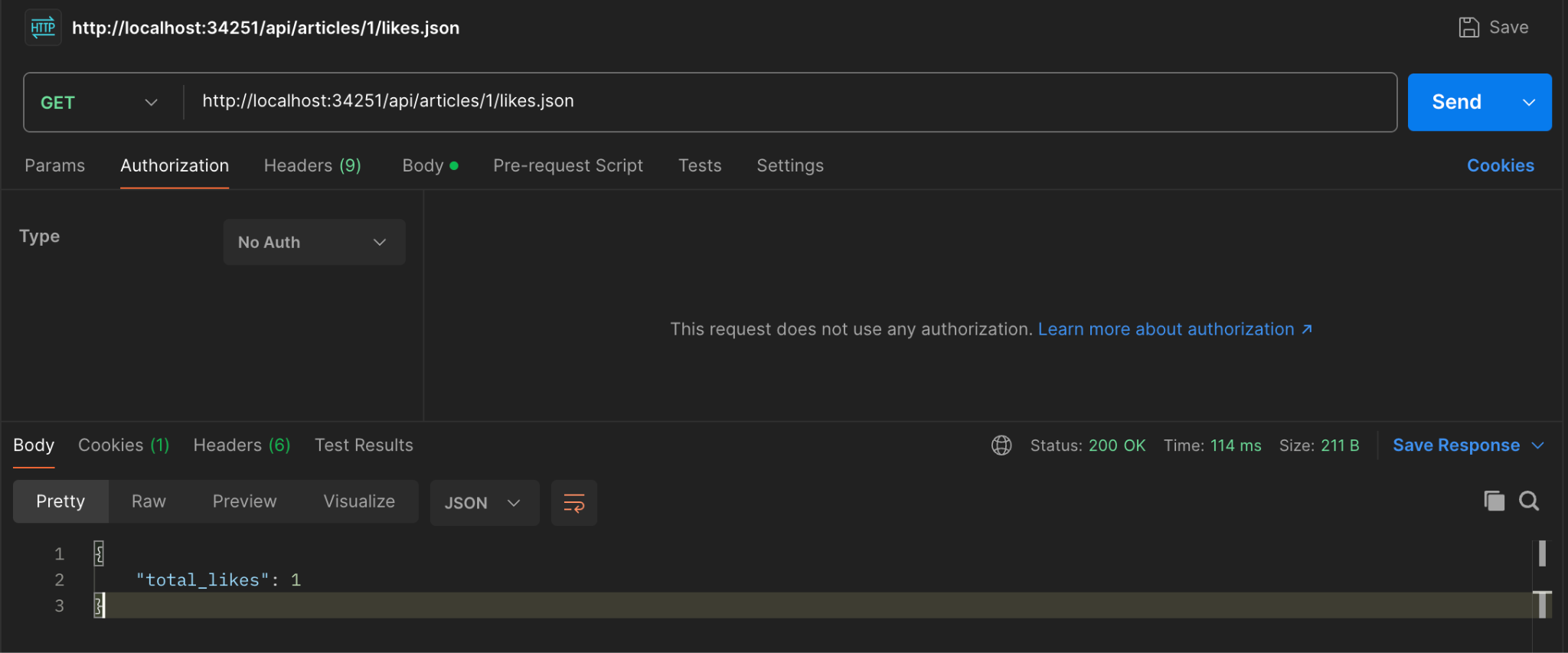
For the API See like count on an article(GET), check with a user who is not logged in.
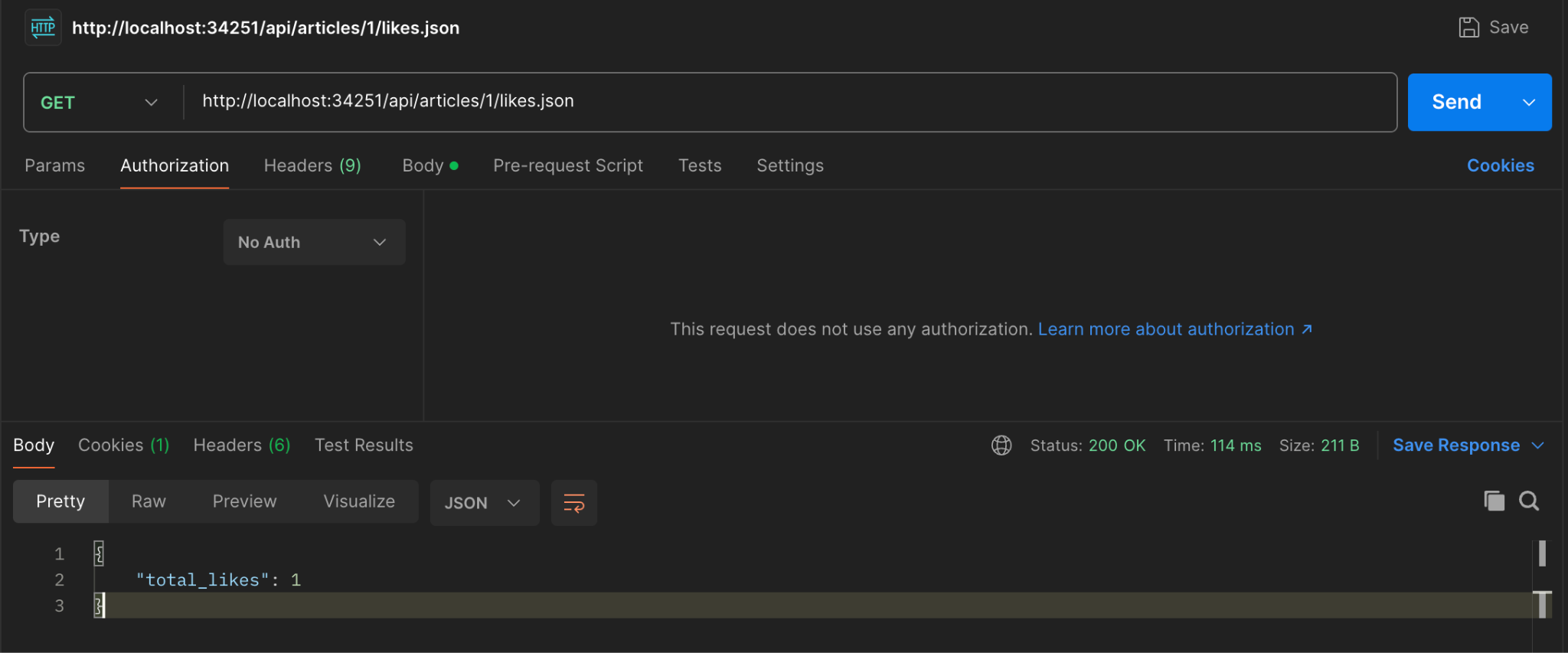
For the API See like count on an article(GET), check with a logged-in user who is not the owner.
You can find the complete source code at: https://github.com/ivc-phampbt/cakephp-authentication
Conclusion
I hope this article helps you understand how CakePHP integrates with the Authorization plugin to implement authorization and can be applied to projects related to CakePHP.
References
https://book.cakephp.org/authorization/2/en/index.html
https://www.rockersinfo.com/php-frameworks/cakephp-development-company/ [Image]